
Suite ELK
Suite ELK
Cette partie documente la mise en place de la suite Elasticsearch - Logstash - Kibana pour API Entreprise. On y trouve une présentation de l'architecture ainsi que des éclaircissements sur les rôles Ansible qui déploient notre configuration ELK.
Méthode d'installation
La mise en oeuvre des trois composants est réalisée par téléchargement et installation des packages Debian.
Gestionnaire de système
Depuis Ubuntu 16.04 LTS Xenial, Systemd est le gestionnaire de services par défaut. C'est donc l'outil utilisé pour la gestion des services Elasticsearch, Logstash et Kibana.
Versions des éléments
Lors de la mise en place de la suite ELK, nous avons choisi la dernière version stable disponible pour les trois produits, à savoir la version 5.5.1.
Attention !
A l'écriture de cette documentation, une contrainte est à prendre en compte pour le choix de la version des trois composants de la suite ELK : la version de Kibana doit être identique à celle d'Elasticsearch - y compris pour la release d'un patch ! Toute autre configuration n'est pas officiellement supportée. Nous mettrons donc à jour tous les éléments de la suite - y compris Logstash.
Les roles Ansible d'installation de ces différents composants réalisent une vérification des checksums des packages ; ne pas oublier de mettre à jour les hashs lors de changement de version.
Présentation de l'infrastructure relative à ELK
L'infrastructure technique à disposition pour le projet API Entreprise est composée de trois serveurs : deux serveurs de production sur lesquels tournent le service API Entreprise en haute disponibilité - les deux machines se répartissant la charge - et un serveur (nom d'hôte watchdoge) destiné à un usage interne à l'équipe, sur lequel sont installés des outils de monitoring, d'intégration continue, de tests...
Les composants de la suite ELK sont répartis de la manière suivante sur l'infrastructure :
Logstash est configuré sur les deux machines de production pour récupérer les logs d'accès au service API Entreprise. Ces logs sont envoyés dans Redis installé sur la machine watchdoge. Le déploiement est paramétré dans le playbook Ansible nommé elk_slave.yml.
Elasticsearch et Kibana sont installés sur watchdoge - tout comme Redis ; Logstash est lui aussi configuré sur ce serveur pour récupérer les logs depuis le Redis et les envoyer dans Elasticsearch. Le déploiement est paramétré dans le playbook Ansible elk_master.yml.
Du point de vue de la suite ELK, l'infrastructure technique est divisée en deux groupes Ansible : elk_slave et _elk__master.
Le rôle et la configuration des différents services Elasticsearch, Logstash et Kibana sont décris dans la suite de ce document.
Configuration des services
Elasticsearch
Elasticsearch est un serveur de base de données NoSQL basé sur la bibliothèque Apache Lucene. Il permet d'indexer des données et d'y faire des recherches plein texte ; tout ceci à travers une API Restfull. Le format de stockage des données ainsi que le format d'interaction avec l'API Rest est en JSON.
N'hésitez pas à consulter la documentation officielle - la première partie "Gettting Started" est une bonne introduction au fonctionnement ainsi qu'au vocabulaire utilisé.
Nous utilisons Elasticsearch pour y stocker les logs d'accès à API Entreprise. Ceci afin de pouvoir générer des statistiques et faire du monitoring sur l'utilisation de notre service (nombre et contexte d'appels, quotas de retour en erreurs, ...)
Paramétrage
Elasticsearch est installé sur l'hôte Watchdoge. C'est une installation "basique" car il s'agit du seul node de toute l'infrastructure. L'ensemble des éléments de configuration du package Debian d'Elasticsearch est disponible dans la documentation officielle. Seul les principaux sont documentés ci-dessous :
Le fichier de configuration système
/etc/default/elasticsearchpermet de paramétrer différentes variables d'environnements relatives au fonctionnement d'Elasticsearch (utilisateur, répertoire des données, répertoire des logs, ...). Il s'agit des valeurs par défauts écrasées par les celles définies dans le fichier de configuration de l'instance Elasticsearch.Le dossier
/etc/elasticsearch/contient les deux fichiers de configuration d'un serveur Elasticsearch :elasticsearch.ymletlog4j2.propertiesLe répertoire home
/usr/share/elasticsearch/contient les fichiers binaires et les différents plugins.Les données Elasticsearch sont stockées dans le répertoire
/opt/elasticsearch/data/.Les logs sont écrits dans le répertoire
/var/log/elasticsearch/.
L'installation d'Elasticsearch est réalisée par le rôle Ansible elasticsearch.
Configuration des index
Les index (au sens d'Elasticsearch) sont exclusivement créés par Logstash. Le paramétrage de ces derniers est détaillé ci-après, dans la documentation de Logstash.
Problème connu
Pour requêter l'API Elasticsearch depuis une autre IP il faut ajouter une ligne et en commenter une autre dans /etc/elasticsearch/elasticsearch.yml :
Référence à la doc et la discussion liée
Logstash
Logstash est un outil d'agrégation de données. Nous l'utilisons pour récupérer les logs générés par les instances d'API Entreprise afin de les indexer dans Elasticsearch. La documentation complète de l'outil est disponible ici.
Pour résumer, configurer Logstash revient à configurer un _pipeline _détaillant :
les différentes sources de données à récupérer.
la manière - optionnelle - de modifier ces données.
la destination des données (après modification éventuelle).
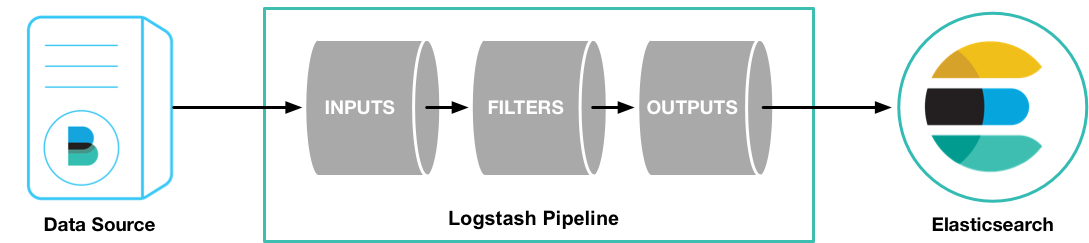
L'outil met à disposition une multitude de plugins permettant de récupérer des données depuis différentes sources (inputs) - fichiers de logs, base de données, redis, irc, websockets... - de les modifier (filters) et de les distribuer vers autant de destination (outputs).
Liste des services analysés
Les logs des services ci-dessous sont récupérés par Logstash et indexés dans Elasticsearch.
siade_production
siade_staging
siade_sandbox
watchdoge_production
watchdoge_sandbox
sirene_production
sirene_sandbox
Description du pipeline Logstash
L'infrastructure serveur est composée de trois machines : deux machines de production (identique) sur lesquelles tournent le service API Entreprise et un autre serveur sur lequel est installée Elasticsearch. Logstash est installé sur chacune de ces machines, et chaque instance de Logstash possède sa propre configuration.
Sur les serveurs de production, Logstash récupère en input les logs d'accès au service API Entreprise dans les fichiers générés par la gem logstasher (cette librairie écrit les logs d'accès à une instance d'application Rails directement au format de données JSON, le format des données indexées dans Elasticsearch). Pour des raisons de performances, ces logs ne sont pas directement envoyés à Elasticsearch mais dans un Redis. Redis joue ici le rôle de pile dans le cas où la charge de logs générés se révèlerait trop conséquente. Cette instance de logstash est déployée par le rôle Ansible logstash_gatherer sur les deux serveurs de production.
Sur le serveur hôte d'Elasticsearch - watchdoge, _l'instance de Logstash lit en _input les logs présents dans le Redis et les index dans Elasticsearch. Cette configuration de logstash est déployée par le rôle Ansible logstash_processor.
Paramétrage des index
Logstash créé les index Elasticsearch lorsqu'il y envoie les logs.
Les index sont nommés de la manière suivante : logstash-YYYY.MM.DD. Logstash se base sur la date du log pour savoir dans quel index l'ajouter. Si l'index n'existe pas, Logstash le créé.
Un template est mis en place pour que chaque index créé par Logstash hérite de la même configuration : Elasticsearch n'étant composé que d'un seul node, ces index n'auront aucune replica shards.
Kibana
Kibana est un outil permettant de faire de la data visualisation sur des données indexées dans un serveur Elasticsearch. Il propose un outil de recherche et différents templates (graphes en batons, listes, diagrammes circulaires, ...) de visualisation de données.
Paramétrage
Il y a peu de paramétrage pour Kibana. Le service est installé sur la machine _watchdoge _et accessible à l'adresse kibana.entreprise.api.gouv.fr
Last updated